Don't let your CMS wreck your content - part 1
Content management systems (CMS) make publishing and managing web content easier. But some systems have limiting features, or are set up in ways that aren't helpful. In this article, we look at page titles and CMS behaviour to watch out for.
The importance of the page <title>
The title plays a crucial role in search engine optimisation. Words used in the title are possibly the most important source of keywords. The title also helps people find and re-find content. It acts as the label for entries in:
- Search results
- Browser favourites or bookmark lists (though users can edit it as they save a page)
- Tabs and the browser history
- Social media linking (on Facebook and Google+ for example. You can add extra metadata fields to provide alternative titles for some platforms, but this is extra data to create and manage).
So it is important that the title is accurate, meaningful and concise. It must identify the page and give users a good sense of what the content is about.
The need for some automation
Before content management systems existed, lots of web pages were published without a title, or with a boilerplate title like "Template – add title here". Many web writers forgot or didn't know about the importance of creating a title. This is still a problem for documents created outside a publishing system — PDF and DOC files, mainly.
To address this problem most systems are now set up to generate the page title automatically. This is a good idea, but it's not always done well. Even when it is, titles sometimes need a little extra that only an editor can provide.
Allow editorial control and provide training
The best approach is to have the system generate an interim title. Then a web writer or editor can edit it before the page gets published. The default could be the main heading plus the site name. Using this approach, a page will never be published without a title and you'll always have editorial control over this important piece of content.
Don't rely on automation alone. As the rest of this article will show, there are problems with any formula you might try to use.
You should train web writers so they understand the role of the title, how your content management system creates it, and how to edit it. An added benefit is that they'll then know they need to write a title for non-HTML documents published online.
Common approaches to automation
Main heading is used as the title
Many systems are set up to use the main page heading ('About us', 'Contact us', 'Our services', 'Our publications' and so on) as the title. But this creates pages that are 'orphans'—content is not labelled as coming from your site.
Your pages will be harder to identify in browser bookmarks or favourites, as the image below illustrates.
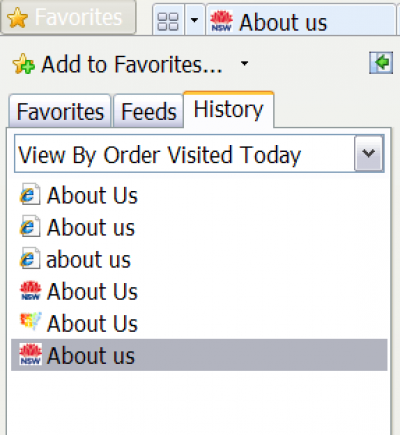
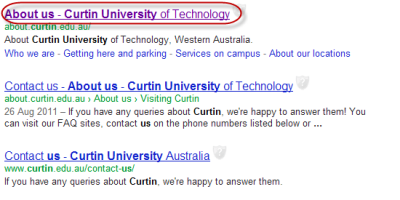
In search results, Google will often compensate for this by adding your site name. Bing doesn't seem to, and other search engines may not either.
Main heading plus the site name is used as the title
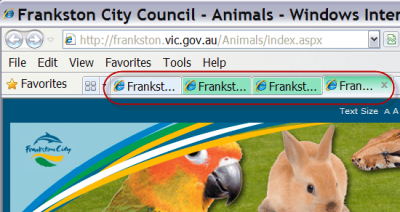
Some systems add the site name to the main heading, which solves the orphan content problem. But if the site name is added in front of the page topic, it pushes the topic terms away from the left edge of the content. This can make it harder to skim over search results or entries in the browser bookmarks or history. And tab labels become useless, especially if you have more than one page from the same site open, as the image below shows.
So it's better to add the site name after the page topic.
But sometimes this still won't provide enough context or keywords to identify the page. For example, an author creates a page called 'Kids and teens' in the library section of a local government website. The page is about library collections and programs for young people, but the title ends up being 'Kids and teens, East Gippsland Shire Council'.

Adding folder names to add context
Some systems try to solve this by adding labels from the folder hierarchy to the heading when creating the page title. However, this can lead to:
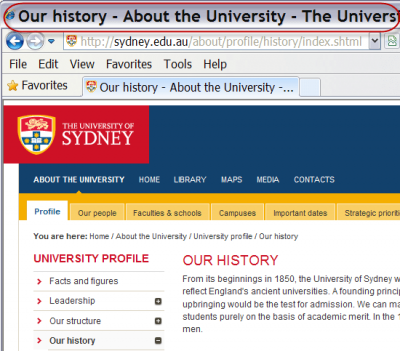
- Wordy titles. The first example below is titled 'Our history – About the University – The University of Sydney'. It could have been the more concise 'History of the University of Sydney'
- Very long titles, particularly if the hierarchy is deep
- Ambiguous titles if part of the hierarchy is skipped to avoid long titles. The second example below has the title 'Program of events – About the University – The University of Sydney'. There's no hint that the page is about events at the London Olympics involving members of the university's community.
And this approach doesn’t allow you to add alternative keywords when you might need to.
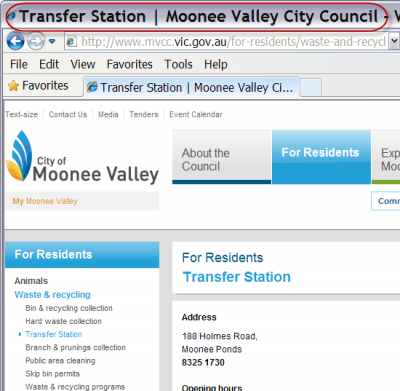
For example, sometimes writers use the official name of a service or facility, but the name may not be known by all users. Local councils sometimes refer to rubbish tips as ‘transfer stations’ because they provide a recycling service as well as dumping rubbish in landfill. It would be useful to have a title such as ‘Transfer station (rubbish, recycling), Moonee Valley City Council’ for this page. Then users who aren’t familiar with ‘transfer station’ will recognise that this is the page they are looking for.
One label for the heading, title and menu
The most restrictive approach I’ve seen is where the system uses the same label for the main heading, title and navigation menus. This can force writers to be very concise and drop keywords to avoid creating sub-menu labels that repeat the keyword from the menu label above. Again, page titles end up being ambiguous. In the example shown below, writing to accommodate short menu labels leads to ambiguous titles such as ‘Part 1 – Preliminary’ and ‘Schedule 1’.
If you can't edit your automated title, what can you do?
It is ideal to have a system that allows you to edit the automated title. However, if your current system doesn't, and you can't get it changed, you'll need to focus on improving the content elements that the title is generated from. Most often this will be the main heading. And each of the headings in the examples above could have been improved to make better titles.
Related articles
Web writing course
Learn how to write and design content that's easy to find, read, and use.
We run live online training for individuals and groups.
Book a course at https://4syllables.com.au/